📚 Bookshelf
📜 Contents
👈 Prev
👉 Next
Chapter 11: Pig
- Pig is made up of two pieces:
- The language used to express data flows, called Pig Latin.
- The execution environment to run Pig Latin programs. There are currently two environments: local execution in a single JVM and distributed execution on a Hadoop cluster.
A Pig Latin program is made up of a series of operations, or transformations, that are applied to the input data to produce output. Taken as a whole, the operations describe a data flow, which the Pig execution environment translates into an executable representation and then runs. Under the covers, Pig turns the transformations into a series of MapReduce jobs, but as a programmer you are mostly unaware of this, which allows you to focus on the data rather than the nature of the execution.
-
Pig runs as a client-side application. Even if you want to run Pig on a Hadoop cluster, there is nothing extra to install on the cluster: Pig launches jobs and interacts with HDFS (or other Hadoop filesystems) from your workstation.
There are three ways of executing Pig programs, all of which work in both local and MapReduce mode:
- Script Pig can run a script file that contains Pig commands. For example, pig script.pig runs the commands in the local file script.pig. Alternatively, for very short scripts, you can use the -e option to run a script specified as a string on the command line.
- Grunt Grunt is an interactive shell for running Pig commands. Grunt is started when no file is specified for Pig to run and the -e option is not used. It is also possible to run Pig scripts from within Grunt using run and exec.
- Embedded You can run Pig programs from Java using the PigServer class, much like you can use JDBC to run SQL programs from Java. For programmatic access to Grunt, use PigRunner.
- Let’s look at a simple example by writing the program to calculate the maximum recorded temperature by year for the weather dataset in Pig Latin. The complete program is only a few lines long:
-- max_temp.pig: Finds the maximum temperature by year records = LOAD 'input/ncdc/micro-tab/sample.txt' AS (year:chararray, temperature:int, quality:int); filtered_records = FILTER records BY temperature != 9999 AND (quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9); grouped_records = GROUP filtered_records BY year; max_temp = FOREACH grouped_records GENERATE group, MAX(filtered_records.temperature); DUMP max_temp; -
A bag is just an unordered collection of tuples, which in Pig Latin is represented using curly braces.
-
Creating a cut-down dataset is an art, as ideally it should be rich enough to cover all the cases to exercise your queries (the completeness property), yet small enough to make sense to the programmer (the conciseness property).
-
Having seen Pig in action, it might seem that Pig Latin is similar to SQL. The presence of such operators as GROUP BY and DESCRIBE reinforces this impression. However, there are several differences between the two languages, and between Pig and relational database management systems (RDBMSs) in general.
The most significant difference is that Pig Latin is a data flow programming language, whereas SQL is a declarative programming language. In other words, a Pig Latin program is a step-by-step set of operations on an input relation, in which each step is a single transformation. By contrast, SQL statements are a set of constraints that, taken together, define the output. In many ways, programming in Pig Latin is like working at the level of an RDBMS query planner, which figures out how to turn a declarative statement into a system of steps.
-
Perhaps not all the input data is needed (because later statements filter it, for example), so it would be pointless to load it. The point is that it makes no sense to start any processing until the whole flow is defined. Similarly, Pig validates the GROUP and FOREACH…GENERATE statements, and adds them to the logical plan without executing them. The trigger for Pig to start execution is the DUMP statement. At that point, the logical plan is compiled into a physical plan and executed.
-
In interactive mode, STORE acts like DUMP and will always trigger execution (this includes the run command), but in batch mode it will not (this includes the exec command). The reason for this is efficiency. In batch mode, Pig will parse the whole script to see whether there are any optimizations that could be made to limit the amount of data to be written to or read from disk.
-
Pig Latin relational operators
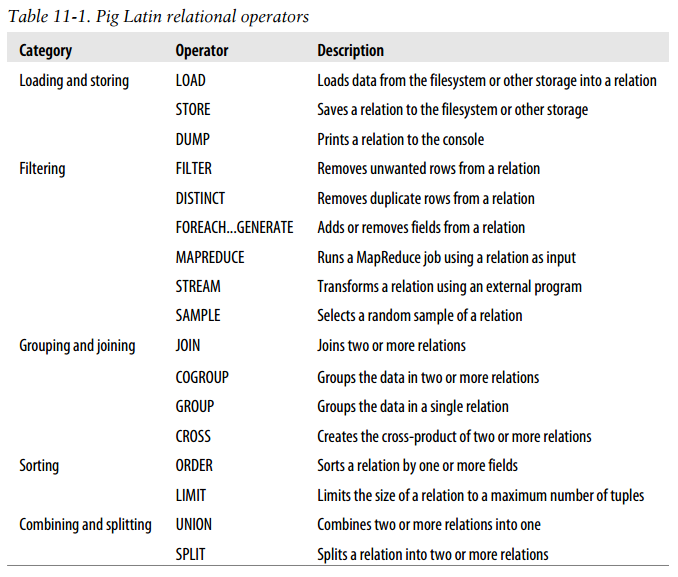
-
Pig Latin diagnostic operators

-
Pig Latin macro and UDF statements

-
A relation in Pig may have an associated schema, which gives the fields in the relation names and types.
- Functions in Pig come in four types:
- Eval function A function that takes one or more expressions and returns another expression. Some eval functions are aggregate functions, which means they operate on a bag of data to produce a scalar value.
- Filter function A special type of eval function that returns a logical Boolean result. As the name suggests, filter functions are used in the FILTER operator to remove unwanted rows.
- Load function A function that specifies how to load data into a relation from external storage.
- Store function A function that specifies how to save the contents of a relation to external storage.
- Filter UDFs are all subclasses of FilterFunc, which itself is a subclass of EvalFunc. We’ll look at EvalFunc in more detail later, but for the moment just note that, in essence, EvalFunc looks like the following class:
public abstract class EvalFunc<T> { public abstract T exec(Tuple input) throws IOException; } - However, there is a better way, which is to tell Pig the types of the fields that the function expects. The getArgToFuncMapping() method on EvalFunc is provided for precisely this reason. We can override it to tell Pig that the first field should be an integer:
@Override public List<FuncSpec> getArgToFuncMapping() throws FrontendException { List<FuncSpec> funcSpecs = new ArrayList<FuncSpec>(); funcSpecs.add(new FuncSpec(this.getClass().getName(), new Schema(new Schema.FieldSchema(null, DataType.INTEGER)))); return funcSpecs; } -
An eval function extends the EvalFunc class, parameterized by the type of the return value.
-
Sometimes you want to use a function that is provided by a Java library, but without going to the effort of writing a UDF. Dynamic invokers allow you to do this by calling Java methods directly from a Pig script. The trade-off is that method calls are made via reflection, which can impose significant overhead when called for every record in a large dataset. So for scripts that are run repeatedly, a dedicated UDF is normally preferred.
-
A LoadFunc will typically use an existing underlying InputFormat to create records, with the LoadFunc providing the logic for turning the records into Pig tuples.
Pig calls setLocation() on a LoadFunc to pass the input location to the loader.
Next, Pig calls the getInputFormat() method to create a RecordReader for each split, just like in MapReduce.
The Pig runtime calls getNext() repeatedly, and the load function reads tuples from the reader until the reader reaches the last record in its split.
It is the responsibility of the getNext() implementation to turn lines of the input file into Tuple objects.
- Consider the relations A and B:
grunt> DUMP A; (2,Tie) (4,Coat) (3,Hat) (1,Scarf) grunt> DUMP B; (Joe,2) (Hank,4) (Ali,0) (Eve,3) (Hank,2) - You should use the general join operator when all the relations being joined are too large to fit in memory. If one of the relations is small enough to fit in memory, there is a special type of join called a fragment replicate join, which is implemented by distributing the small input to all the mappers and performing a map-side join using an inmemory lookup table against the (fragmented) larger relation. There is a special syntax for telling Pig to use a fragment replicate join:
grunt> C = JOIN A BY $0, B BY $1 USING "replicated";The first relation must be the large one, followed by one or more small ones (all of which must fit in memory).
- JOIN always gives a flat structure: a set of tuples. The COGROUP statement is similar to JOIN, but instead creates a nested set of output tuples. This can be useful if you want to exploit the structure in subsequent statements:
grunt> D = COGROUP A BY $0, B BY $1; grunt> DUMP D; (0,{},{(Ali,0)}) (1,{(1,Scarf)},{}) (2,{(2,Tie)},{(Joe,2),(Hank,2)}) (3,{(3,Hat)},{(Eve,3)}) (4,{(4,Coat)},{(Hank,4)})COGROUP generates a tuple for each unique grouping key. The first field of each tuple is the key, and the remaining fields are bags of tuples from the relations with a matching key.
If for a particular key a relation has no matching key, the bag for that relation is empty.
-
Pig Latin includes the cross-product operator (also known as the cartesian product), which joins every tuple in a relation with every tuple in a second relation (and with every tuple in further relations if supplied).
-
Although COGROUP groups the data in two or more relations, the GROUP statement groups the data in a single relation. GROUP supports grouping by more than equality of keys: you can use an expression or user-defined function as the group key.
-
If you want to impose an order on the output, you can use the ORDER operator to sort a relation by one or more fields. The default sort order compares fields of the same type using the natural ordering, and different types are given an arbitrary, but deterministic, ordering.
Any further processing on a sorted relation is not guaranteed to retain its order. It is for this reason that it is usual to perform the ORDER operation just before retrieving the output.
The LIMIT statement is useful for limiting the number of results as a quick and dirty way to get a sample of a relation; prototyping (the ILLUSTRATE command) should be preferred for generating more representative samples of the data.
-
To explicitly set the number of reducers you want for each job, you can use a PARALLEL clause for operators that run in the reduce phase. These include all the grouping and joining operators (GROUP, COGROUP, JOIN, CROSS), as well as DISTINCT and ORDER.
-
Pig supports parameter substitution, where parameters in the script are substituted with values supplied at runtime. Parameters are denoted by identifiers prefixed with a $ character.
Parameters can be specified when launching Pig, using the -param option, one for each parameter. You can also put parameters in a file and pass them to Pig using the -param_file option.